GraphQL - the current trend in integrations
For many years, SOAP and REST integration ruled the world. In recent years, we have increasingly come across the term GraphQL. Experts have been arguing in many articles whether GraphQL will replace REST. The answer to these questions is likely to come only in the future. However, as they say—"those who are prepared are not surprised". So let's take a look under the hood of this tool for a moment in the following paragraphs.
A practical example
To introduce the problem, let's use a simple example. Imagine a social network where millions of posts, photos, comments, and likes are accumulating. Over the years of this network, the amount of content has grown exponentially. But as a single user, I only want to see my friends' posts in my feed, be able to filter only relevant comments, or see who likes my vacation photos. In the case of the REST architecture, at this point, I have to use at least three different endpoints, meaning that three separate requests are running in the background. Moreover, life is getting faster, and the user usually doesn't want to wait for data longer than absolutely necessary (usually, he starts to get nervous after about half a second).
It may not surprise you that GraphQL was originally developed by Facebook. Its first version was released in 2012 and started to be used for loading data into mobile apps. Three years later, the GraphQL specification was then opened and presented to the public: https://graphql.org/
So what is GraphQL?
As the name suggests, GraphQL is defined as a "query language." It is used to efficiently retrieve data from the server side. The tool relies on a few basic principles that differentiate it from a REST interface.
Only one endpoint
Perhaps the biggest difference between GraphQL vs. REST is that we only ever use one endpoint and always use the POST method. This is a significant simplification for the user. At this point, GraphQL is kind of an intermediary that contacts the right service based on our request.
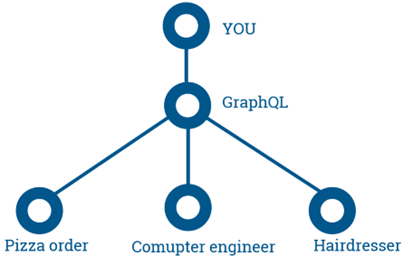
Image 1: Comparison of GraphQL to a real-life situation
Returns only the requested data
One of the main features is that GraphQL returns exactly the data you ask for, nothing more and nothing less. The client must first define the structure of the query. This structure is also the format in which the response is returned. This means that when creating the query, I can set which data I really want to return, in what order I want to return it, and which data I don't need. Items that I don't need are simply omitted from the query. This, of course, increases the efficiency of the operation and also makes it easier for the client to navigate through the returned data.
Just to remind you—in the REST API, the entire payload is always returned in all circumstances. You always get all the data on each request without any selection.
Versioning
GraphQL schema is unique and the only "source of truth." By its definition, this schema is always up-to-date, and all new features are reflected in it. Managing older versions of this schema is a registry that behaves similarly to, say, the GIT versioning tool. Even so, GraphQL suppresses older versions quite a bit and doesn't put as much emphasis on them as the REST API, which is strictly versioned.
Working with documentation
When it comes to API documentation, I'm sure everyone is familiar with tools like Swagger or Apiary. By default, GraphQL uses automatically generated documentation based on a schema. This documentation is quite clearly visible in GraphQL Playground, which is a simple "built-in" client for making requests. Of course, thanks to the automatic generation, we can always be sure that the documentation is up-to-date. It doesn't have to be maintained by the developers, which often results in out-of-date versions.
Basic concepts
After listing the features, I will now add an explanation of a few key terms. The very foundation of any GraphQL server is the Schema. Basically, it is a precise description of what data and in what format can be requested from the GraphQL API. It defines the different structures and the relationships between them. At the same time, the schema defines the operations that the client can perform against the server.
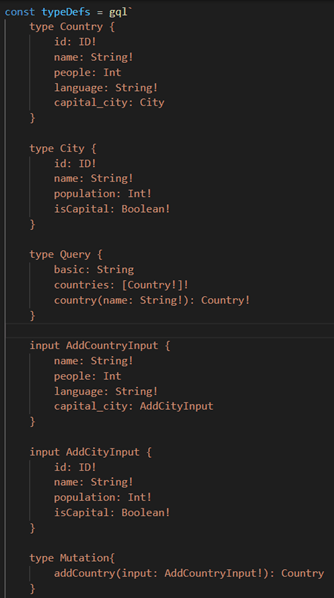
Image 2: Example of a schema
GraphQL uses 3 basic types of operations - Query, Mutation, and Subscription.
Query is a type of operation that returns data according to a defined structure. We can say that it is similar to rest GET.
Mutation, on the other hand, is an operation that changes the data in some way, writes it. We compare it to the well-known POST method.
Subscription is a bit of a specialty and the icing on the cake in the GraphQL world. This operation works with data in real time. The client uses Subscription to maintain a long-term connection with the server (usually via websockets) and waits for any change in the data or any other event. At that point, the server sends a response to the client.
I will also mention here the concept of Resolver. As the translation suggests, it is basically a resolver of the client's request. In other words, it's a function written in a programming language that determines what is executed on a given request. This can be well visualized in the case of the Mutation operation, where the resolver is a function that, for example, writes data to a certain table in a database.
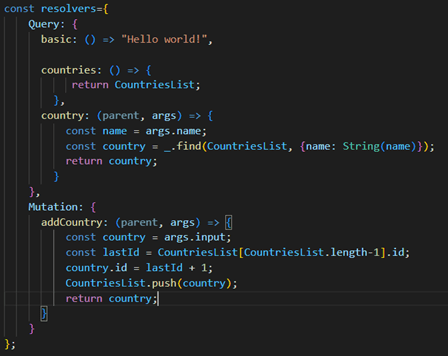
Image 3: This is what resolvers can look like
From the following figure, we can see one of the other advantages of GraphQL. Validation against the schema takes place before the actual execution of the request by the resolver. This eliminates any unvalidated requests, which do not put any load on the server at that moment because they do not even reach it.

Image 4: Request cycle sent by the client
Recent developments
As I mentioned at the beginning of this article, GraphQL was originally developed by Facebook to eliminate some of the shortcomings of REST. Since then, however, there has been a big growth, and today we can see this technology in the development teams of huge companies like Netflix, Amazon, or GitHub. It's also managed to build a fairly stable and active community that organizes various talks, meetups, conferences, or summits on GraphQL-related topics. So it seems that the potential here is great and it wouldn't be a surprise at all if you'll soon encounter this technology on your projects.
It should be kept in mind that GraphQL was developed as another alternative for working with APIs. But it certainly won't fully replace REST and SOAP, at least not anytime soon. Of course, each of these tools has its advantages and disadvantages. Nor is this article meant to say that one is better than the other or that GraphQL is completely universal. The decision of which tool to use should certainly be tailored to the nature of the project, the experience of the team members, and so on.
Therefore, I would like to conclude by inviting you to a webinar on December 7, 2022. If you are interested in this topic, I would be happy to share my experience with you. We will look at GraphQL a bit more from a practical point of view, try to create our own simple GraphQL server, and get data through the client.

Autor: Michal Jirka
My career in testing started while I was still studying at university, it was February 2017. I chose Tesena, and it was more than a good choice! Since then, I have been involved in numerous projects for clients in the field of test automation. At the same time, I have been learning from our most experienced experts through internal activities. For some time now, I have also been dedicated to mentoring, training, webinars... I simply enjoy sharing the experiences I have gained! I look forward to meeting you at any event, whether it be in the online world or, even better, in person :)