GraphQL – aktuální trend v oblasti integrací
Dlouhé roky vládlo světu integrací SOAP a REST. Poslední roky se stále častěji setkáváme s pojmem GraphQL. Odborníci se v mnoha článcích předhání v názorech, jestli GraphQL nahradí REST. Odpověď na tyto otázky pravděpodobně přinese až budoucnost. Nicméně jak se říká – „kdo je připraven, není překvapen“. Pojďme se tedy pod pokličku tohoto nástroje na chvilku podívat v následujících odstavcích.
Příklad z praxe
Pro uvedení do problému použijeme jednoduchý příklad. Představme si sociální síť, kde se hromadí miliony příspěvků, fotek, komentářů a lajků. Za léta fungování této sítě množství obsahu exponenciálně roste. Já jakožto jeden jediný uživatel ale chci ve svém feedu vidět pouze příspěvky mých přátel, být schopen si filtrovat pouze relevantní komentáře, případně vidět, kdo lajkuje mé fotky z dovolené. V případě RESTové architektury v tuhle chvíli musím využít minimálně tři různé endpointy, to znamená, že na pozadí proběhnou tři samostatné requesty. Navíc život se zrychluje a uživatel většinou nechce na data čekat déle, než je nezbytně nutné (obvykle začíná být nervózní zhruba po půl vteřině).
Možná vás nepřekvapí, že GraphQL bylo původně vyvinuto Facebookem. Jeho první verze vyšla na svět v roce 2012 a začala se používat pro načítání dat do mobilní aplikace. O tři roky později pak byla GraphQL specifikace otevřena a představena veřejnosti: https://graphql.org/
Co je tedy GraphQL?
Jak již název napovídá, GraphQL je definován jako „query language“ (dotazovací jazyk). Slouží k efektivnímu získání dat ze strany serveru. Nástroj se opírá o několik základních principů, kterými se odlišuje od RESTového rozhraní.
Pouze 1 endpoint
Možná největší odlišností GraphQL vs. REST je, že používáme vždy pouze jeden endpoint a vždy metodu POST. Pro uživatele je to výrazné zjednodušení práce. GraphQL v tuhle chvíli představuje takového prostředníka, který na základě našeho požadavku kontaktuje tu správnou službu.
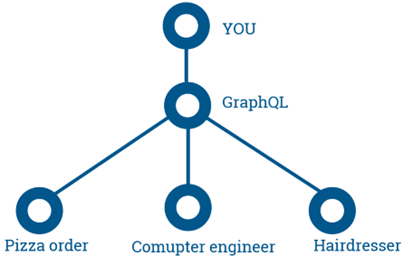
Obr 1: Přirovnání GraphQL k situaci z reálného života
Vrací pouze požadovaná data
Jedním z hlavních znaků je, že GraphQL vrací přesně ta data, o která si požádáte, nic víc a nic míň. Klient nejprve musí zadefinovat strukturu dotazu. Tato struktura je zároveň i formátem, ve kterém se vrací odpověď. Znamená to, že již při tvorbě dotazu si nastavím, která data opravdu chci vrátit, v jakém pořadí je chci vrátit a která data naopak nepotřebuji. Položky, které nepotřebuji, z dotazu jednoduše vynechám. To samozřejmě zvyšuje efektivitu provedené operace a zároveň klientovi usnadňuje orientaci v navrácených datech.
Jenom pro připomenutí – v REST API se vrací za všech okolností vždy celý payload, při každém requestu dostáváte vždy všechna data bez možnosti výběru.
Verzování
GraphQL schéma je jediným a unikátním „zdrojem pravdy“. Z jeho definice vyplývá, že toto schéma je vždy up-to-date a jsou do něj promítány všechny novinky. Správa starších verzí tohoto schématu je registrem, který se chová podobně jako třeba verzovací nástroj GIT. Nicméně i tak GraphQL starší verze dost potlačuje a neklade na ně takový důraz, jako právě REST API, které je striktně verzováno.
Práce s dokumentací
Co se týče API dokumentací, určitě každý zná nástroje jako Swagger nebo Apiary. GraphQL defaultně používá automaticky generovanou dokumentaci, která vychází ze schématu. Tato dokumentace je poměrně přehledně viditelná v GraphQL Playground, což je jednoduchý „vestavěný“ klient pro provolávání requestů. Díky automatickému generování máme samozřejmě vždy jistotu, že je dokumentace aktuální, nemusí být udržována ze strany vývojářů, což s sebou často přináší neaktuálnost verzí.
Základní pojmy
Po výčtu vlastností nyní přidám vysvětlení několika nejdůležitějších pojmů. Naprostým základem každého GraphQL serveru je Schema. V podstatě se jedná o přesný popis toho, jaká data a v jakém formátu lze od GraphQL API požadovat. Definuje jednotlivé struktury a vztahy mezi nimi. Zároveň jsou ve schématu definovány operace, které může klient vůči serveru vykonávat.
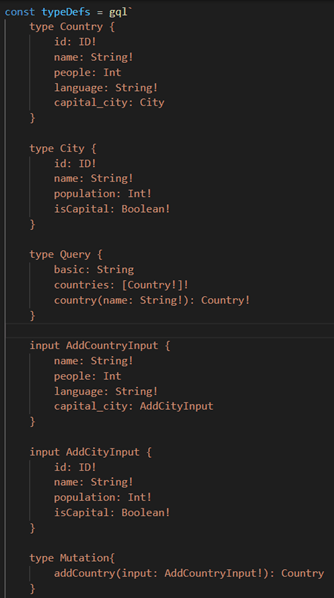
Obr. 2: Příklad schématu
GraphQL používá 3 základní typy operací – Query, Mutation a Subscription.
Query je typ operace, která vrací data dle zadefinované struktury. Můžeme říct, že je obdobou restového GETu.
Mutation je naopak operace, která data nějakým způsobem mění, zapisuje. Přirovnáváme ji tedy ke známé metodě POST.
Subscription je tak trochu specialitka a třešnička na dortu v GraphQL světě. Tato operace totiž pracuje s daty v reálném čase. Klient pomocí Subscription udržuje dlouhodobé spojení se serverem (většinou přes websockety) a čeká na jakoukoliv změnu v datech nebo jinou událost. V tu chvíli server posílá odpověď klientovi.
Zmíním zde ještě také pojem Resolver. Jak již překlad napovídá, je to v podstatě řešitel klientova requestu. Jinými slovy – je to funkce napsaná v programovacím jazyce, která určuje co se při daném requestu vykoná. Dobře si to lze představit na případu operace Mutation, kdy resolver je funkce, která např. zapisuje data do určité tabulky v databázi.
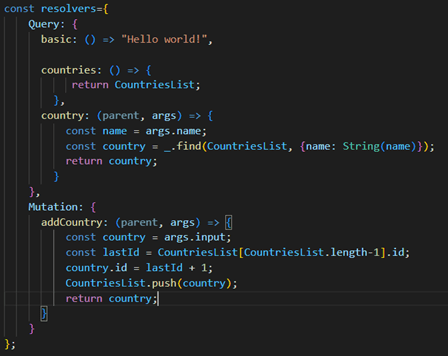
Obr. 3: Takto mohou vypadat resolvery
Z následujícího obrázku lze vyčíst jednu z dalších výhod GraphQL. Validace vůči schématu totiž probíhá ještě před samotnou exekucí requestu resolverem. Eliminuje to tak případné nevalidní požadavky, které v tu chvíli nijak nezatíží server, protože se k němu ani nedostanou.

Obr. 4: Cyklus requestu zaslaného klientem
Vývoj v poslední době
Jak jsem zmínil v úvodu článku, GraphQL bylo původně vyvinuto Facebookem za účelem eliminovat některé nedostatky RESTu. Od té doby ale došlo k velkému rozmachu, dnes již se s touto technologií můžeme setkat i ve vývojářských týmech obrovských společností jako jsou Netflix, Amazon nebo GitHub. Podařilo se taky vybudovat poměrně stabilní a aktivní komunitu, která pořádá nejrůznější přednášky, meetupy, konference nebo summity na témata spojená s GraphQL. Zdá se tedy, že potenciál je v zde velký a nebylo by vůbec překvapením, kdybyste se s touto technologií brzy setkali i na vašich projektech.
Je třeba mít na paměti, že GraphQL bylo vyvinuto jako další alternativa pro práci s API. Určitě ale plně nenahradí protokoly REST a SOAP, alespoň ne v nejbližší době. Každý z těchto nástrojů má samozřejmě své výhody a nevýhody. Ani tento článek nemá za cíl říct, že jeden je lepší než ten druhý nebo že GraphQL je naprosto univerzální. Rozhodnutí, který nástroj se bude používat je určitě třeba přizpůsobit povaze projektu, zkušenostem členů týmu a podobně.
Proto bych vás chtěl závěrem pozvat na webinář, který se uskuteční 7. 12. 2022. Jestli vás toto téma zajímá, rád se s vámi podělím o své zkušenosti. Podíváme se na GraphQL trochu více z praktického hlediska, zkusíme si vytvořit vlastní jednoduchý GraphQL server a přes klienta získávat data.
Chcete se o GraphQL dozvědět více?
Podívejte se na záznam webináře o GraphQL na našem YouTube kanále!

Autor: Michal Jirka
Moje kariéra v testingu začala ještě při studiu na vysoké škole, v kalendáři byl tehdy únor 2017. Vybral jsem si Tesenu a volba to byla víc než dobrá! Od té doby jsem byl součástí mnoha projektů pro klienty v oblasti automatizace testů. Zároveň jsem se v rámci interních aktivit učil od našich nejzkušenějších odborníků. Již delší dobu se věnuji také mentoringu, školením, webinářům... zkrátka mě baví získané zkušenosti předávat dál! Těším se, že se potkáme na jakékoliv akci, ať už v online světě nebo ještě lépe osobně :)